

人们每天上传至云端的档案数量,多达一亿张相片、十亿份文件… 更别提数位影音、交易、生物医疗… 每天全球所创造的资料量高达2.5艾字节(exabyes, 即1000,000,000,000,000,000)。
但资料量大就是大数据吗? 究竟什么是大数据? 又为何大数据会在近几年突然兴盛起来? 时常耳闻的Hadoop, MapReduce, Spark 技术又是什么呢?
今天,就让我们来聊聊什么是大数据(Big Data)。
大数据的源起

“储存成本”与“资料取得成本”因科技进步而大幅下降,造就了这个年代大数据的兴起。
30年前,1TB档案存储的成本为16亿美金,如今一个1TB的硬盘不到100美金。同时间,全球各行业的资料量成长更是急速攀升;根据预估,从2013年至2020年间将成长10倍的资料量,资料总量将从4.4ZB增加至44ZB。
以天文学为例,2000年美国太空总署在新墨西哥州发起的史隆数位化巡天 (Sloan Digital Sky Survey)专案启动时,望远镜在短短几周内收集到的资料,已经比天文学历史上总共收集的资料还要多。
在生物医学领域,新型的基因仪三天内即可测序1.8 TB的量,使的以往传统定序方法需花10年的工作,现在1天即可完成。在金融领域,以银行卡、股票、外汇等金融业务为例,该类业务的交易峰值每秒可达万笔之上。
Google每天要处理超过24 千兆字节的资料,这意味着其每天的资料处理量是美国国家图书馆所有纸质出版物所含资料量的上千倍。 Facebook每天处理500亿张的上传相片 ,每天人们在网站上点击”赞”(Like)按钮、或留言次数大约有数十亿次。
YouTube的使用者人数已突破十亿人,几乎是全体互联网使用者人数的三分之一,而全球的使用者每天在YouTube 上观看影片的总时数达上亿小时。在Twitter上,每秒钟平均有6000多条推文发布,每天平均约五亿条推文。
千禧年开始,天文学、海洋学、生物工程、电脑科学,到智慧型手机的流行,科学家发现:仰赖于科技的进步(传感器、智慧型手机),资料的取得成本相比过去开始大幅地下降──过去十多年蒐集的资料,今朝一夕之间即能达成。
也因为取得数据不再是科学研究最大的困难,如何“储存”、“挖掘”海量数据,并成功地“沟通”分析结果,成为新的瓶颈与研究重点。
接下来,我们将进一步介绍大数据的定义、特性,与发展重点。
什么是大数据?

大数据意指资料的规模巨大,以致无法透过传统的方式在一定时间内进行储存、运算与分析。至于“大”是多大,则各家定义不一,有兆字节(TB)、千兆字节(PB)、百万兆字节(EB)、甚至更大的规模单位;然而,若真要找到符合这么大规模数据量的企业倒也是不容易。
事实上,根据451 Research 的资料科学家 Matt Aslett,他将大数据定义为“以前因为科技所限而忽略的资料”,讨论这些以前无法储存、分析的资料。如本文第一段所言,由于在近年来储存成本降低与资料获取量变大,因而能观察到不曾注意过的商业趋势,让企业做出更全面的考量。
无论企业规模大小,我们应注重的不仅是数据量本身,而应将“大数据”作为在科学研究与商业方法的运营心态:大数据需要全新的处理方式,以新型的储存运算方法分析数据、产出沟通图表,并将该分析结果视为一种战略资产。
大数据的特性?

目前大部份的机构将大数据的特性归类为“3V”,包括资料量 (Volume)、资料类型 (Variety)与资料传输速度 (Velocity)。
Volume – 资料量
无论是天文学、生物医疗、金融、联网物间连线、社群互动…每分每秒都正在生成庞大的数据量,如同上述所说的TB、PB、EB规模单位。
Variety – 资料多样性
举一个简单的例子:
│资料类型│ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │…
就算上述资料量高达 1 TB,采用传统统计方法仍能很容易地找到资料规律。也因此,真正困难的问题在于分析多样化的资料──从文字、位置、语音、影像、图片、交易数据、类比讯号… 等结构化与非结构化包罗万象的资料,彼此间能进行交互分析、寻找数据间的关联性。
Velocity – 资料即时性
大数据亦强调资料的时效性。随着使用者每秒都在产生大量的数据回馈,过去三五年的资料已毫无用处── 一旦资料串流到运算服务器,企业便须立即进行分析、即时得到结果并立即做出反应修正,才能发挥资料的最大价值。
目前台湾真正能符合大数据“3V”定义的企业微乎其微,在数据分析上更是不可能──通常是由资料科学团队向企业的IT部门登入企业服务器取得资料,除了量与多样性已难以达到以外,在“即时性”这一点上便不符合;唯有企业内部自建即时的资料分析团队并随时产出分析反馈,方能称作大数据分析。
大数据的发展重点

我们在上述提到了如何用非传统的方法“储存”、“挖掘”与“沟通”资料以挖掘崭新商业机会,是当前的一大技术方向。
讲到大数据,我们便不能不提与之息息相关的软件技术──“Hadoop”。
Hadoop 由Java语言撰写,是Apache软件基金会发展的开源软件框架。不但免费、扩充性高、部属快速,同时还能自动分散系统负荷,在大数据实作技术上非常受欢迎。
Hadoop的核心主要由两个部分所构成,一为资料储存:“Hadoop分散式档案系统(Hadoop Distributed File System)”;二为资料处理:“Hadoop MapReduce”。
– Hadoop分散式档案系统 (Hadoop Distributed File System, HDFS):
由多达数百万个丛集(Cluster)所组成,每个丛集有近数千台用来储存资料的服务器,被称为“节点”(Node)。其中包括主服务器(Master Node)与从服务器(Slave Node)。
每一份大型档案储存进来时,都会被切割成一个个的资料块 (Block),并同时将每个资料块复制成多份、放在从服务器上保管。当某台服务器出问题时、导致资料块遗失或遭破坏时,主服务器就会在其他从服务器上寻找副本复制一个新的版本,维持每一个资料块都备有好几份的状态。
简单来说, Hadoop 默认的想法是所有的Node 都有机会坏掉,所以会用大量备份的方式预防资料发生问题。另一方面,储存在该系统上的资料虽然相当庞大、又被分散到数个不同的服务器,但透过特殊技术,当档案被读取时,看起来仍会是连续的资料,使用者不会察觉资料是零碎的被切割储存起来。
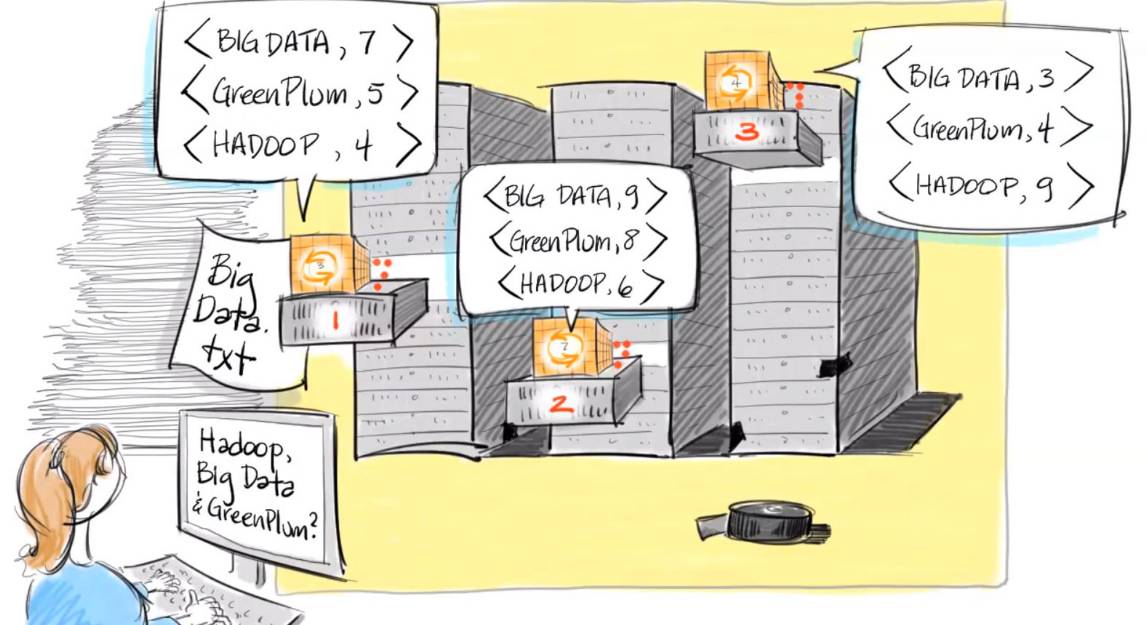
– Hadoop MapReduce:
MapReduce是一种计算模型,分为Map和Reduce两项功能。
“Map”功能会先将大资料拆成小资料,并以Key-Value格式备用。比如有数千万份的资料传入,Map会计算每个字出现的次数;比如computer这个字出现了一次、便以(computer, 1)这样的 (Key, Value) 格式表示。
“Reduce”则是汇整,意即汇整所有相同的Key并计算出现的总次数。
简单来说,Map仅是在各节点上计算少量数据,而Reduce则是统计各地数据、将结果送回主服务器进行公布。MapReduce的好处在于无须将所有资料都搬回中央去运算,而能在各地先简单的处理完毕后、再回传数据,如此更有效率。
总而言之,Hadoop分散式档案储存系统(HDFS)是一个超大型的储存空间,并透过Hadoop MapReduce进行运算。
Hadoop成功解决了档案存放、档案备份、资料处理等问题,因而应用广泛,成为大数据的主流技术。Amazon、Facebook、IBM和Yahoo皆采取Hadoop作为大数据的环境。
事实上近两三年来,Apache软件基金会另一个新星“Spark”隐隐有取代Hadoop MapReduce的态势。
在大规模资料的计算、分析上,排序作业的处理时间,一直是个重要的指标。相较于Hadoop MapReduce在做运算时需要将中间产生的数据存在硬盘中,因此会有读写资料的延迟问题;Spark使用了内存内运算技术,能在资料尚未写入硬盘时即在内存内分析运算,速度比Hadoop MapReduce可以快到100倍。
许多人误以为Spark将取代Hadoop。然而,Spark没有分散式档案管理功能,因而必须依赖Hadoop的HDFS作为解决方案。作为与Hadoop 相容而且执行速度更快的开源软件,来势汹汹的Spark想取代的其实是Hadoop MapReduce。
另一方面,Spark 提供了丰富而且易用的API,更适合让开发者在实作机器学习算法。2015年6月,IBM宣布加入Apache Spark社群,以及多项与Spark专案相关的计画,IBM将此次的大动作宣称为:“可能是未来10年最重要的开放源码新计画”,计画培育超过一百万名资料科学家。
资料分析 – 机器学习

介绍完了Hadoop基础架构后,让我们来看看资料分析上的最热门技术──“机器学习”。
如何从大数据中挖掘资料规律,以改善科学或商业决策,以手动方式探索资料集的传统统计分析,已难以应付大数据的量与种类。唯有透过“机器学习”,以电脑算法达成比以往更深入的分析。
机器学习发端于1980年代,是人工智能的一项分支。透过算法模型建构,使电脑能从大量的历史数据中学习规律,从而能识别资料、或预测未来规律。
从Google搜寻技术与广告,到医疗、金融、工业、零售、基础建设… 机器学习的应用涵盖各行各业,一夕之间即可能有着天翻地覆的革新。
后续的系列文章中,我们将带领读者进一步了解机器学习的发展潜能。
资料沟通 – 资料视觉化

随着“数据导向决策”的时代来临,资料科学家在分析完数据后,如何成功地将分析结果传递出去、使企业接收到该资讯呢? 资料视觉化 (Data Visualization)的重要性与潜在的庞大商机因此愈发被凸显出来。
人类的大脑在阅读图像画面的速度远比文字更快。资讯视觉化的优势在于──以一目了然的方式呈现资料分析结果,比查阅试算数据或书面报告更有效率。
“Tableau软件”和微软开发的“Power BI”产品皆主打在资料分析后,将自动产生简洁易懂的资讯图表,并随着新增的数据分析结果生成仪表板(Dashboard),供使用者查询动态报表、指标管理等服务。
我们在本篇文章中介绍了大数据的精神意义──大数据无统一定义,代表着传统的储存、分析技术难以应付的高维度资料。实际上大数据的特性包括了3V:量(Volume)、多样性(Variety)与即时性(Velocity)。
我们也介绍了大数据在“储存”、“挖掘”与“沟通”的重点发展方向,从Hadoop、机器学习与资料视觉化,大数据的相关技术日新月异。唯有建立合适的资料科学团队、将数据视为企业的策略性资产,方能发掘无所不在的商业机会,在此波数据浪潮下创造竞争优势。

长
按
关
注
长按识别二维码,关注德润资本
德润资本是一家以上市公司产业整合为核心,聚焦全球并购重组、政府产业引导基金、定增基金、公司市值管理以及境外上市筹划夹层投融资等业务的投顾一体化基金管理公司。
共有条评论 网友评论