

过去 50 年,人类 GDP 增长根本的动力是摩尔定律。20 世纪 60 年代中期,大规模集成电路(后来是超大规模集成电路)的出现,不仅带动了整个 IT 行业的技术革命,而且导致了全球的自动化和信息化,这是在过去的半个世纪里拉动世界经济增长的根本动力(虽然在中国还有房地产和基本建设,但是在世界范围内,这个市场是在萎缩的)。
来源:厚势 (ID:iHoushi)作者:吴军博士
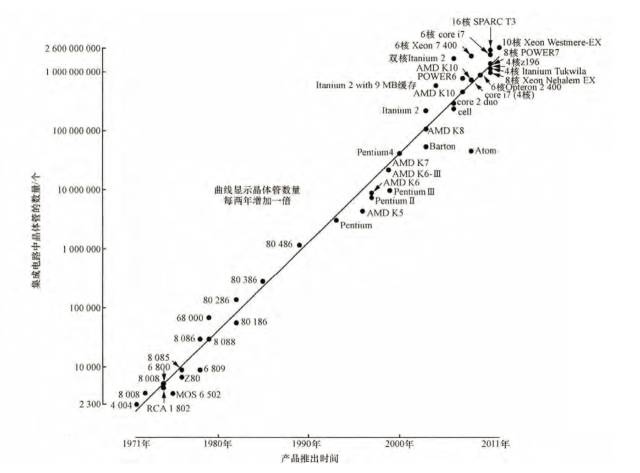
图 1 微处理器中晶体管数量变化与摩尔定律
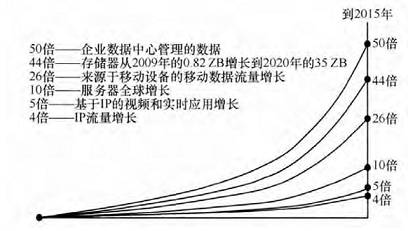
图 1 为 1971 ~ 2011 年微处理器中晶体管数量的变化,图中的点是不同时期具有代表性的处理器。
摩尔定律带来的一个结果就是互联网的兴起以及产业的数字化,而这也带来了一个没有预想到的结果,就是各种数据量的急剧增长(如图 2 所示),最终导致了大数据的应用。摩尔定律和大数据共同带来的另一个结果就是:「机器智能」将成为可能。
01
机器智能及其早期发展
自从 1946 年第一台电子计算机诞生,人类就开始思考是否有一天计算机能够在智力上超过人类。
早在 1950 年,计算机科学的先驱图灵博士就提出了一种衡量机器(包括计算机)是否有类似于人类智能的方法:让一台机器和一个人坐在幕后,与一个人展开对话(回答人的问题),而这个人无法辨别和他讲话的是另一个人还是一台机器,那么称这台机器具有和人等同的智能。这种方法被称为「图灵测试」,如图 3 所示。
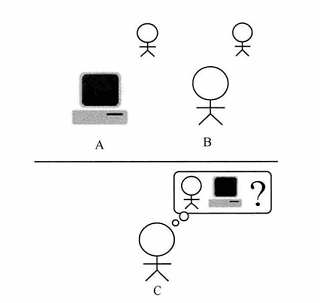
图 3 图灵测试
02
从人工智能到数据驱动的时代
在机器智能的发展史上,贾里尼克是一个划时代的人物。1972 年,康奈尔大学教授贾里尼克来到 IBM 沃森实验室进行学术休假,并且承担 IBM 研制智能计算机的工作。当时,计算机专家们认为如果计算机实现了下面几件事情中的一件,就可以认为它有图灵所说的「智能」:
语音识别;
机器翻译;
自动回答问题。
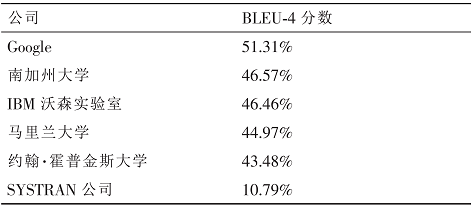
最能够说明数据对解决机器翻译等智能问题有帮助的是 2005 年 NIST 对全世界各家机器翻译系统评测的结果。
之前没有做过机器翻译的 Google 不仅一举夺得了各项评比的第一名,而且将其它单位的系统远远抛在了后面。
例如在阿拉伯语到英语翻译的封闭集测试中,Google 系统的 BLEU 评分为 51.31%,领先第二名将近 5%,而提高这 5 个百分点在过去需要研究 7~10年;在开放集的测试中,Google 以 51.37% 的得分比第二名领先了 17%,可以说整整领先了一代人的水平。
表 1 2005 年 NIST 从阿拉伯语到英语的翻译(封闭集)评比结果
03
从大量的数据到大数据
数据驱动的方法需要大量的数据。从理论上讲,切比雪夫不等式保证了在具有大量代表性的数据后,统计模型的准确性。
从应用上讲,Google 等公司的成功也验证了这一点。既然数据是非常有用的,如果具有更多、更完备、全方位的数据,就可能从中挖掘出很多预想不到的惊喜。「大数据」这个概念就在这样的背景下应运而生。
什么是大数据?现在很多人都爱讲这个时髦的词,但是大多数人对它的理解不仅有很大的局限性,有些甚至完全是错误的。
在随后的几十年,盖洛普公司不断地改进采样方法,力求统计准确,但是它对美国大选结果的预测是大局(全国)尚准确,但是细节(每一个州)常常出错,因为再好的采样方法也有考虑不周全之处。
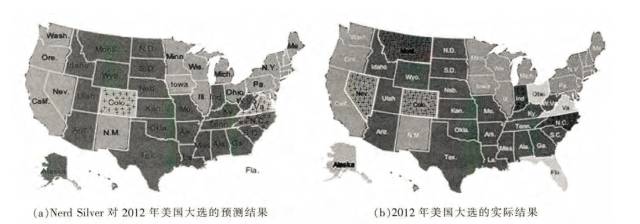
04
大数据和机器智能
现在大数据炙手可热的原因不仅是各行各业都可以通过对数据的分析极大地提升自身的业务,更重要的是它将带来机器智能的全面革命,并且最终改变世界的产业格局和社会生活。
摩尔定律的作用是保证计算机的计算能力和存储能力能够适应解决复杂智能问题的需求;
大数据的多维度和完备性特点是保证智能性问题能够找到答案的关键;
数学模型则是将现实生活中的问题转化成计算的桥梁。
本文的重点是阐述大数据扮演的角色,下面通过 Google 的两个例子来说明。
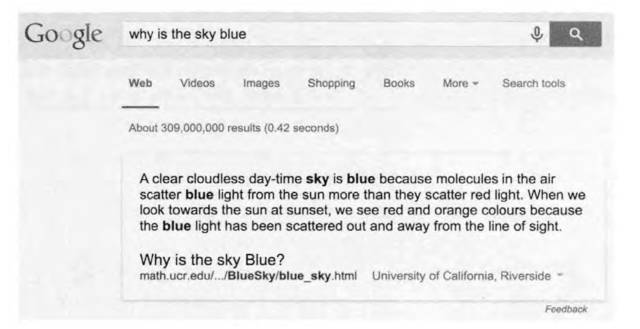
第一个前提只有 Google 等少数大公司具备,而学术界不具备,因此决定了 Google 而非学术界最早解决图灵留下的这个难题。图 5 为 Google 自动问答的实例。
首先,自动驾驶汽车项目是 Google 街景项目的延伸,Google 自动驾驶汽车能去的地方都是它扫过街的地方,这个汽车在行驶到任何地方时,对周围的环境是非常了解的,不像过去那些研究所里研制的自动驾驶汽车每到一处要临时识别目标。
05
大数据和机器智能的关键技术
实现大数据的应用和机器智能涉及很多关键技术,涵盖了计算机科学、电机工程、通信、应用数学和认知科学等许多方面,本文重点介绍其中最主要的几项。
大数据离不开数据,而数据的收集非常关键。与传统的利用采样收集数据不同,大数据需要全面地、在无意间收集各种可能有用的数据。强调「无意间」是因为有时可以收集的数据会变形,不具有统计意义,关于央视收视率调查的例子就说明了这个道理。
摩尔定律使存储成本成倍下降,但是当大数据出现后,数据量增长的速度可能超过摩尔定律增长的速度(如图 2 所示)。例如,Google 眼镜可能将人一辈子看到的事情全部记录下来,如果这件事做成了,会彻底改变人们对世界,甚至对自己人生的了解。但是,将这些视频(包括音频)数据都存下来不是一件容易的事情。
对于互联网的网页数据、公司运营的日志数据、用户使用互联网习惯的数据,虽然其数据量大,但是颗粒度都很小(一个字段一般只有几个字节到几十个字节),因此它们的表示(描述)、检索和随机访问并不是大问题。
但是,对于富媒体数据(如视频),要想随机访问其中一个画面就不是一件容易的事情。还有很多比网络富媒体颗粒度大得多的数据,例如很多和医疗相关的数据,一个基本单元就几百兆甚至更多。目前,检索一个词组是件容易的事情,但是检索一段基因就不容易。除了医疗,很多行业(如半导体设计、飞机设计制造)的数据量都很大。
使用大数据,相当于在一堆沙子中淘金,不经过处理的原始数据给不出新知识,大数据能产生的效益在很大程度上取决于使用和挖掘数据的水平。在 Google,至少有四成的工程师每天在处理数据。
大数据不同于过去为了某个特定目的获取或者产生的数据,在结构和格式上比较规范,大数据的原始数据常常是杂乱无章的,因此「从沙子里淘金」的本领是使用大数据的必要条件。
在第 5 节的机器自动问答的例子中,虽然问题的答案存在于网页之中,但是答案的内容通常是零碎地分布在不同网页里,对网页的结构、内容进行分析就成为了使用大数据的先决条件。而对于文本大数据来说,自然语言理解技术是使用它们的前提。
大数据由于数据量大而且完备,一旦丢失,损失将是巨大的,而一旦被盗取,后果更是不可想象。因此,大数据的安全性是 IT 领域新的挑战。
目前,机器智能做得最好的领域都有一个共同的特点,就是找到了把实际问题变成计算的数学模型和智能算法。
为了让计算机发挥更大的作用,变得更加智能,需要在数学模型研究上进行更大的投入,而这需要一个漫长的技术积累,很难在一夜之间有突破,因此除了长期坚持研究,别无他法。
06
机器智能和未来社会
机器智能可以帮助改善人类的生活,但是人们在欢呼机器智能到来的同时,是否准备好了它对未来社会带来的冲击?2011 年德国提出工业 4.0 的概念,即通过数字化和智能化提升制造业的水平。
其核心是通过智能机器、大数据分析来帮助工人甚至取代工人,实现制造业的全面智能化。这在提高设计、制造和供应销售效率的同时,也会大大减少产业工人的数量。在中国,全球最大的 OEM 制造商富士康,一直在研制取代生产线上工人的工业机器人。
未来将有上百万的机器人取代装配线上的工人,这使得工人们不再需要到生产线上从事繁重而重复的工作,也使工厂里的工人数量大幅度地减少。
07
总结
机器智能曾经是无数代人的梦想。在 1946 年人类制造出第一台电子计算机以后,这个梦想似乎离人们非常近了,但是直到上个世纪末,机器的智能水平还比较低。主要有两个原因:
更多原创精品,点击关键词获取

共有条评论 网友评论