
在牛顿开辟力学之前,物理学主要活动是研究行星和天体运动,即占星术。16世纪著名的丹麦占星家第谷,作为有史以来视力最好的人,用其一生观察与收集了非常精确的天体运动数据。作为第谷的关门弟子,开普勒的视力不行,无法自己观察和收集天体运行数据,但他继承了占星家第谷毕生积累的大数据,研究数据后发现行星轨道不是圆周形的,而是椭圆形的;行星公转的速度不等匀速等规律。经过9年的努力,开普勒最终用简介的数学公式发表了开普勒三定律,即椭圆定律、面积定律和调和定律,第一次用数学语言描述了行星的运行规律。70年后,现代近代物理学开创者艾萨克·牛顿于1687年在《自然哲学的数学原理》发表了万有引力定律,应用万有引力定律和牛顿第二定律严格地证明了开普勒三定律,也证明了星体按照开普勒三定律运动的原因。
自牛顿开始,物理学以及其他科学便插上了数学的翅膀,得到了飞速发展,以至认为:如果一个学科不能用数学来表达,这门学科就算不上科学。用数学公式或数学模型来描述一个现象或者一个规律,即找到机理模型,成为各门学科科学家孜孜追求的目标;有了数学公式和模型,发表的论文也才有档次。计算机学科的发展,更突出了数学模型的重要,一个现象或规律只有用数学模型表达,计算机才能计算求解。实际上将现实物理与化学现象抽象成数学模型虽然困难,但却是科学研究最省力的方法,数学模型可以大大减少了实验量和观测量。如同有了开普勒三定律后,预测某行星的运动规律,再也不需要对对它进行多年的连续观测了。
本文的标题“化工企业数字化的特征之三:从机理模型到数据模型”,并不是让化工工程师和科学家放弃机理模型转到数据模型,而是在化工生产企业搞生产数字化、在“云大物智移”技术大发展的背景下,解决生产操作问题时,化工厂的建模和数据分析工程师可以不必刻意追求机理模型甚至半机理模型,可以多应用数据模型。从机理模型到数据模型,并非技术的倒退,而是在特定条件下更简单的方法,甚至是迫不得已的方法。
基于机理模型的操作实时优化很困难
化学是一门难以用数学描述的学科,主要是因为分子和原子这个层次变化还是太复杂,所以中学时认为化学是”理科中的文科“,更多是记忆现象和规律。直到大学出现”物理化学“这门课,才真正地用物理和数学的方法来研究化学上的宏观现象,物理化学教材里面大量的热力学和动力学数学公式,化学终于可以像物理一样从几条公里推导出一个庞大的学科体系。从化学到化工,背后机理更复杂,化学变化背后同时存在分子扩散、流体流动、热量传递。尽管如此复杂,化工现象基本还是可以用数学模型来描述,这些化工数学模型基本分布在”物理化学“、“化工热力学”、”化学反应工程“、”单元操作与传递现象“这几门课中。基于这些数学模型,发展出了化工模拟和仿真,可以用计算机做化工设备单元设计和全流程集成优化等工作。
然而真的用流程模拟和仿真来解决工厂中的实际问题,发现还差一大截,计算出来的结果和现场实际并不吻合,对未来一段时间的预测数据和真实测量出来的数据差距还不小,甚至50%的误差都会有。其主要原因是:这些模型是基于一些理想假设、排除非重要因素做了许多简化、模型中还有很多不确定的参数、现场缺乏必要的测量数据。我经常说,一个工艺单元的理论优化空间只有5% (在化工厂,通过参数调整将能耗或物耗减低5%是非常了不起的事情了),用一个误差10%的数学模型去优化计算,计算结果显示的提升到底是模型误差还是真实提升,这个结果没人能说得清。就比如用用磅秤去称金条,谁敢信?所以说,基于机理模型的实时优化(RTO)是一件难度极高的事情,对数据测量精度、模型本身精度、计算速度要求很苛刻,在化工行业成功的案例并不多。
化工厂生产操作可以依靠数据模型
实验室研究需要发现具有普遍性、大范围有效的规律;实验室每一组数据都必须付出人力、金钱和时间的代价。所以实验室研发依靠的是小数据,通过少量数据经过科学家的联想分析后发现现象背后的规律。如果能总结成数学模型,便可以极大地减少实验量,只需少量实验将模型中的参数回归出来,便可以用模型预测未做实验的数据。
工厂生产不同于实验室做研发。化工工厂生产是利用已经建设好的设备和装置、使用安全可靠的工艺、采用合格的原料生产出合格的产品。工厂生产对数据的采集和应用方法与实验室研发大不一样。
第一,化工厂操作与优化的逻辑和方法与实验室不一样。要得到质量一致性的产品,需要采用一致性的设备和工艺参数,即“标准化”是工厂生产管理的重点。即使做优化改进,也要坚持“变更管理”,一旦改变后,形成新的标准。基于PDCA(计划-执行-检查-纠正巩固)循环的标准化与滚动优化是工厂操作管理的基本逻辑。
第二,化工厂获得数据代价与实验室不一样。设备与装置本身已经安装了大量在线仪表,用于过程状态监测以及过程控制。不可在线测量的重要数据,例如原料、中间料以及产品的组成和性质,分析测试实验室会按固定周期进行采样和离线分析化验,补充这些重要数据。所以,工厂不需要付出额外代价来获取数据,采集和应用数据本就是日常工作的一部分。如果工厂安装了实时数据库,工厂则已经积累了海量数据。
第三,化工厂的数据范围与实验室不一样。化工厂是按照生产标准、按照标准设定参数运行的,所以采集到的数据99%都是在工作点附近。除了必然的随机因素导致的随机波动外,数据变化主要由于生产负荷、原料、设备以及催化剂性能衰减、天气变化等边界条件变化所引起。理论上,这些数据的变化可能组合成无限多种状态;但实际上生产负荷设定、原料种类、天气情况实际上都是少量的有限状态,所以总体上化工厂的生产状态是有限数目的。
第四,化工厂应用数据的目的不一样。除了基本的控制回路中,测量数据直接用于过程控制。然而这部分直接作用于过程控制的数据只占总数据量的大约10%,大约90%数据用于过程监控。监控的主要目的是发现异常,即监测设备状态和工艺状态是否偏离标准状态;如果偏离,是什么参数或者什么原因导致。
一个熟练的操作员,天天面对工作范围内的仪表数据,对每块仪表的正常波动范围已经了熟于心。当某块仪表的数据不在他记在心中的范围,操作员便可判断出有异常。再根据以前对此类似异常的分析和处理,基于历史经验,操作员可以直接指出异常原因和处理方法。操作员对异常的识别和处理,并没有应用机理模型,完全基于当前数据本身以及历史数据记录。实际上,化工装置的使用者,无需理解装置是如何设计出来,运行的原理是什么,但需要知道装置的使用方法,正常运行的操作规则和操作方法,故障的识别方法和处理方法。如同我们都在使用手机,只要看懂说明书会使用即可,无需理解手机是怎么制造出来、4G或5G通信的原理是什么。当然,操作人员和管理人员对化工设备和工艺的机理理解越深刻,可做的改进空间越大,这种情况只能说可遇不可求。
从数据到模型有四个层次
我在一篇旧文《大数据没那么神秘:技术篇(1)》中举了一个例子,从数据到模型有四个不同层次。
例如:某简单系统只有一个输入x和一个输出y,历史记录中有10组(x,y)数据。由于测量误差,观测到的y值并不完全准确,含有30%的噪声,记作y_noise, 所以将观测数据组记录为(x,y_noise),见下图。
问:请预测x=1.5时,y值估计为多少?
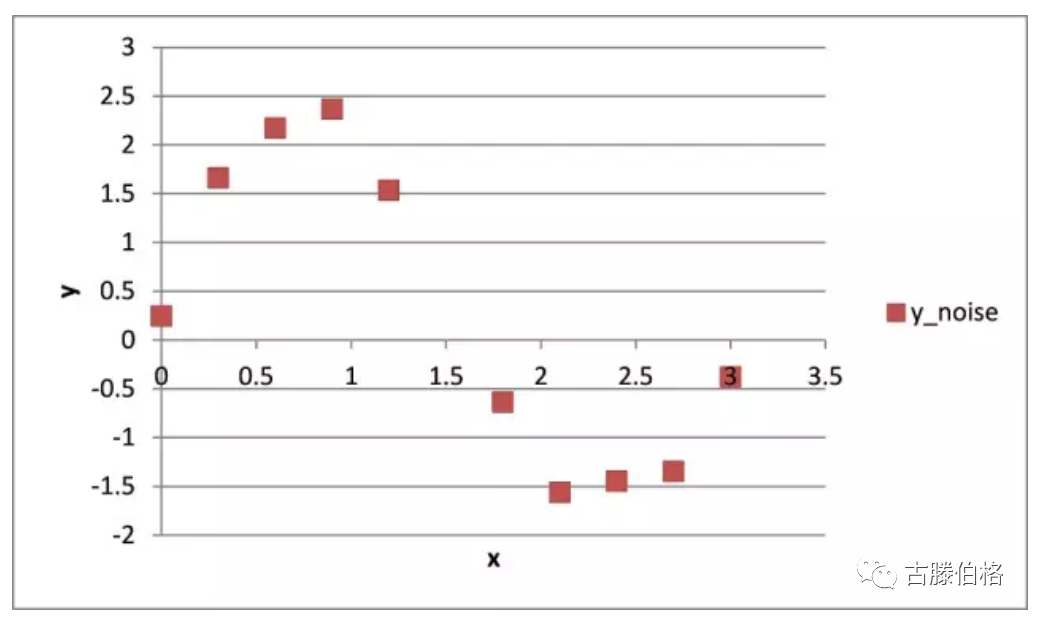
原始观测数据(x,y_noise)
方法1:直接查表:原始数据集中没有x=1.5的数据,那取最接近的数据,即(x=1.8,y=-0.6),即取y=-0.6作为 x=1.5的预测值。
方法2:线性插值:直接将临近两点x=1.2,x=1.8连接成一条直线,从直线上读出x=1.5时,y=0.45
方法3:数值逼近:用一个3次多项式逼近这些观测到的数据点,用所有观测到的数据回归估计3次多项式的所有系数,最终x=1.5时,y=0.50
方法4:模型参数回归:观察这些数据点,图像类似正弦波,所以用函数y=k*sin(b*x)表达,用所有观察到的数据回归参数k和b,得到y=2.026sin(2.013x),最终x=1.5时,y=0.25
这个简单例子,确实说明了机理模型的优越性,机理模型可以消除测量中的噪声,预测更准确。这个例子x=1.5刚好是函数变化最激烈(即斜率最大)的地方,所以在此附近y变化较大,不同方法的预测结果差别也大。如果问x=2.5的预测值,此处函数斜率较小,y的变化较小,所以不同方法的预测值差别将不大。
所谓的数据模型或者机器学习模型,在本质上都是插值或者数值逼近,只是采用多维和非线性模型。如果数据足够密,直接查表也有足够的精度。
实际化工生产过程一般都属于此图中x=2.5这种情况,操作点一般在关键参数相对平稳的地方(否则过程对参数太灵敏的话,则过程无法稳定控制)。另外,前文已说明,化工生产状态是有限数目的。所以从原理上,数据模型可以用于化工生产操作指导。
数据模型更依靠算力与暴力
从对计算机要求上看,机理模型通常对硬盘、内存和CPU要求比较低,只需在硬盘存储少量模型参数即可,计算时占用的内存和消耗的CPU并不高。当然,对含有大型精馏塔模型的模拟计算或者严格的CFD计算,机理模型计算时对计算机还是有非常高的要求。
数据模型更依靠计算机算力和存储,首先需要将各种工况的原始数据存储起来,这对存储有需求;其次,数据模型,例如神经网络模型,特别是模型学习时,占用的内存和消耗的CPU非常高。极端情况下,如果工况数据足够多足够密,直接采用暴力查表也可行,但是高维数据查表极其耗内存和耗CPU。所以,数据模型更依靠算力与暴力,现在“云大物智移”的ICT技术条件发展,为暴力算法提供了条件。
数据模型对数据有更高的要求
要正确地采用数据模型来解决问题,数据需要满足完备性、遍历性、准确性。准确性比较好理解,重点说明完备性和遍历性。
1.数据完备性:要用数据描述或者确定一个工艺状态,所用的数据必须是完整的,即确定最少量的数据来消除系统的自由度,使系统不能自由变化,这便是数据完备性。用代数语言表达,一个系统由n个独立变量和m个独立方程组成,则该系统有(n-m)个自由度,即只要知道任意(n-m)个变量的值,剩下的变量都可以解方程计算出,即已知(n-m)个变量值后,系统便确定了,有了这(n-m)个变量值,数据就完备了,至于是哪(n-m)并不重要。一个系统到底有多少个自由度,化工过程基本都是已知的,例如一个进料为m个组分,有N块塔板的精馏塔,做过精馏塔模拟的工程师都知道,这个精馏塔的自由度是(m+2)+(N+2),(m+2)是进料条件(n个组成,加上温度和压力2个条件),(N+2)是塔条件(包括N块板的压力,和包括热负荷、塔顶塔底采出量和组成的任意2个条件)。
通常我们将测量数据分成四类:a. 不可自由调节的边界输入条件,包括生产负荷、进料条件、环境条件;b.可自由调节的操作条件,例如塔的热负荷,塔压力;c.评价性输出结果,包括出口条件、物耗、能耗;d.内部状态变量,包括设备内部的温度、压力分布等。下图便是一个循环流化床锅炉的变量分类。要满足数据完备性,通常需要测量和收集边界条件、操作条件以及评价性输出结果。
目前化工行业导致数据缺乏完备性,主要还是进料的成分数据。在线成分分析成为化工行业数字化的一个瓶颈,要完善化工行业数字化,必须大力发展包括光谱分析在内的在线成分分析技术。
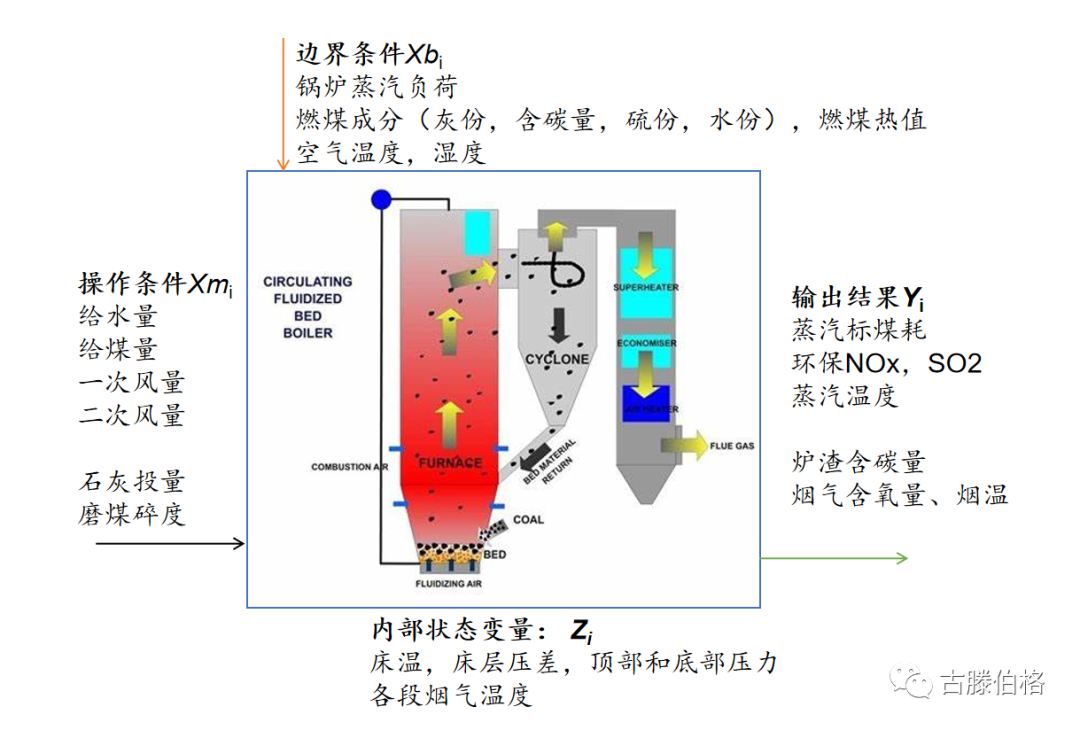
一个循环流化床锅炉的变量分类
2.数据遍历性:要用已有数据模型去预测一个新的状态点的输出结果,则原历史数据必须已经达到过或者接近过这个新状态点,即历史数据遍历过各种状态,这就是数据的遍历性。前文已经指出,化工生产是在有限的生产状态下生产,通常经过三年生产,基本已经经历过90%的可能发生的状态。数据模型本质是查表、是插值,它只能在历史记忆中,通过寻找与待预测点相似的状态点,根据相似历史状态的输出来预测新输出。数据模型没有联想和推断能力,但是,记忆能力已经可以应对有限状态了。
引用圈内冯恩波博士的话,数字化、大数据、人工智能方法,从时空纬度看,都是基于“历史相似性”、“状态遍历性”和“时间连续性”三大原理。“历史相似性”、“状态遍历性”前文已经解释,所谓”“时间连续性”只化工生产装置状态不会发生跳跃性突变,从一个状态到另外一个状态,总是有个或快或慢的过渡过程,这个过渡过程在时间上是连续的。
数据模型也需要降维可视化方法
化工装置,即使一个工艺单元,包含的数据也有很多个,一套普通的精馏塔在DCS上可能有50个左右的仪表数据,化工单元数据属于典型的高维数据。这些仪表数据往往有信息冗余的,某个仪表数据显示异常并不能说明精馏塔操作真发生异常,只有多个仪表互相验证异常时,才是真发生了异常。如此高维的数据,靠内操去判断生产工况的异常,是一件非常辛苦的事情,大脑中必须记住正常工况下各个数据的正常波动范围,也要记住常见异常现象下各个仪表的现实范围。
应用机器学习降维算法,将高维数据降维成2维或者3维空间上,便可以通过在计算机屏幕上显示,操作员便可以通过目视的方式来进行判断是否异常,判断是否偏离历史最佳状态点,进而即时改进操作,减少不作为的损失。
我认为,基于数据的分类算法和降维算法是化工企业数字化在生产操作层面的主要算法,我将在后续文章论述这个观点。
往期文章:

共有条评论 网友评论