
华研数据研究院 颜奇敏
(Strata dataconference 大数据会议专场随笔)
2017年7月12日-2017年7月15日,由世界著名IT界纸媒Oreilly和大数据架构鼻祖cloudera公司主办的strata data conference在北京国际饭店会议中心顺利举办。
这次大会由国内外各大数据龙头企业的创始人、CTO、及数据业务负责人开展了各个行业的培训课程和主题演讲,包括金融、保险、医疗、交通、电商、机器人等领域,介绍了大数据行业的前沿动态,以及各行业在大数据环境下的发展方向。
大数据与人工智能的热潮
学术界在80年代90年代初的人工智能(机器学习)研究就已经开启,近几年在工业界的推动下,掀起了热潮。事实上,理论依据的算法还是很早提出的算法,不同的是当今计算的资源和数据量比先前丰富的多,计算力和数据量的提升便可以达到更好的训练效果从而投入实际的应用也就更加有效率。以海量数据为优势的“大数据”概念就应运而生了。以下就给大家分享一些现今的企业是如何将大数据投入到发展趋势中。

中国银联的数据储备支持:cloudera(世界最权威的大数据平台推行公司之一)
发生在腾讯AI大数据实验室里的大数据研究
2017年5月,腾讯首度在美国西雅图开设人工智能实验室,将用户数据的优势投入到更好的国际化研究生态中。腾讯美国实验室首席数据科学家刘晗向大家展示了腾讯现在大数据产品的三大板块:
一、游戏(game)
腾讯在2016年在游戏产业的收入高达100亿美元。在游戏产品上,分为棋牌和MOBA两大类。棋牌类以大家熟知的《QQ麻将》,MOBA类以最近火热的《王者荣耀》为代表,其中王者荣耀的月活跃用户达到1.6亿。
而在这些炙手可热的产品中,背后所支持则是庞大的大数据资源和算法。腾讯旗下开发的“绝艺”围棋AI产品,号称中国的“AlphaGO”,此前“绝艺是在日本举行的第10届UEC杯电脑围棋冠军。该类产品主要依赖的是海量数据的模仿学习(imitation learning)和强化学习(reinforcementlearning)的模拟器。而MOBA类产品则是依靠更为复杂的移动同步技术,在录入几千场比赛数据的学习下,“机器人”打王者荣耀也可能做到战无不胜,从这里也可以促进游戏产品更多提高玩家体验的灵感。
二、社交(social)
微信的月活跃用户现已到9.38亿。海量的聊天用户数据,为腾讯带来了开发聊天机器人(conversational AI)得天独厚的优势,大平台应用产品形成的反馈机制也可以为开发提供持续优化。自然语言处理(Natural Language Processing)即人类语言转化为计算机语言处理,是聊天机器人开发的核心处理技术,也被誉为人工智能现在最难功课最顶尖的研究领域之一。目前的趋势,如微软的一些相关专家纷纷流入腾讯和国内其他巨头公司,主要也是由于国内用户大平台的优势。
三、内容(content)
由于微信、QQ等广泛的用户数,《天天快报》作为腾讯、在各个应用上都会推送的新闻消息类产品,日活跃量用户数也达到了2500万。而基于搜索和点击量的数据,利用传统机器学习算法的推荐系统(recommendation system),利用点击、搜索、购买等用户行为,为不同用户推送自动订制类新闻消息和广告产品,使得双方的效益都得到最大化。
大数据在滴滴出行的应用
滴滴出行我国目前最大的共享出行平台,为中国4亿多用户提供交通出行服务。滴滴的平台每天会产生超过70TB的新增轨迹原始数据,处理超过200亿次的路径规划请求,并生成超过140亿次定位数。滴滴出行研究院长叶杰平指出,利用以上庞大的数据量,进行位置、路线、推荐系统的优化,可以不断完善用户的出行体验。

滴滴供需监控网络:将地图分割成无数个六边形。每一时刻都在检测每一个六边形,然后在某个六边形里面计算订单数和空车数,计算供需是否平衡
滴滴在内部已经部署了自己的实时监控网络。细化到地图上每一个六边形区域,可实施监测出基于用户请求,区域上可提供服务的车辆数(大于用于请求为正值,小于为负值),通过时间段(周期变量)、位置(连续变量)和二者结合的数据累积,预测在相应时间段某位置的路况,在路况已经出现不平衡之前就作出最优决策,运力调度以及导航优化,以提前调价的方式解决车辆分配不均问题,也可以通过某地发生的活动事件进行供需预测。
除了基于距离调度运力,也同时参考基于用户数据的喜好进行个性化匹配调度。现在滴滴预测功能体系还还推出了“猜您想去”的功能。通过此功能,滴滴可以为一些大型商超、火车站等人流密集场所提供出行解决方案建议,从个人角度可以降低用户发单时候的输入成本,也可以从一定程度上让用户有“惊喜”的使用体验。
机器学习在保险、金融业务上的再发现
中国人寿作为唯一一个保险行业的公司出现在大数据会议上,专场也吸引了不少参会者。中国人寿数据部门,通过多年积累的数据,来挖掘助于业务推动、风险管理和客户服务的产品。
以寿险业务为例,中国人寿与因特尔和cloudera合作,使用现在较为普遍的大数据在线分析平台,因特尔的开源深度学习(DeepLearning)框架用传统机器学习和深度学习的方法,实现寿险业务的再发现。以70万用户的试验数据,将基于产品和基于用户的两种算法得出的产品组合下达给销售人员进行推荐。得到了90%以上的用户的购买反馈。
蚂蚁金服开放平台基于支付宝的海量用户,将强大的支付、营销、数据能力,通过接口等形式开放给第三方合作伙伴,帮助第三方合作伙伴创建更具竞争力的应用。
2016年双十一当天,蚂蚁金服承担阿里交易订单处理到达12万笔/秒,落到数据系统上的压力约为每秒100万次交互。面对这种独特的业务需求,蚂蚁金服完全自主研发的新一代分布式实时图数据库。其设计目标是满足超大规模复杂关系网络在金融领域中的各类应用场景,既要支撑线上高并发的低延迟的实时查询需求,又要满足大规模模型训练的迭代运算。数据库支持了包括风控关系网络,资金关系网络,都达到百亿个节点,万亿条边的海量数据规模,支撑着支付的风险控制,反洗钱,反套现,金融案件审理,和好友推荐,理财资讯推荐等众多的业务。
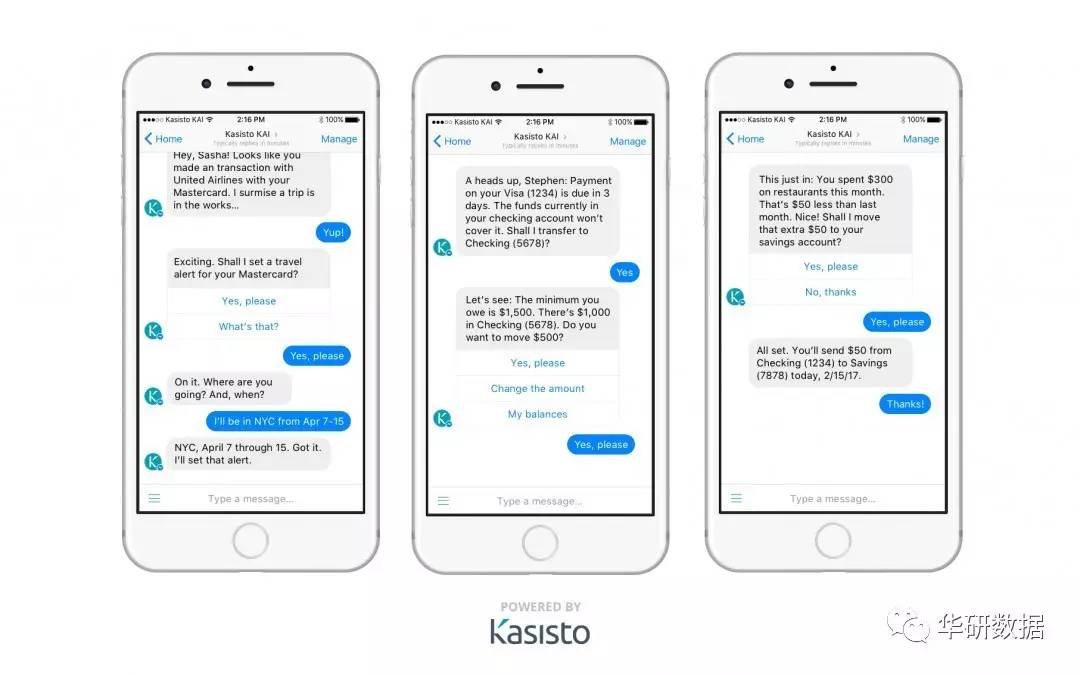
配图来自kasisto:人工智能识别交易信息,验证和积累用户行为
Cloudflower:现实世界里的主动学习
大会不乏谷歌和微软等国际大公司来进行技术培训讲话,Cloudflower这个硅谷新星却受到了参会者的瞩目。
人工智能前期最重要的环节,是将得到的数据进行清洗和训练。有了足够的训练基础,才能投放到实际应用之中。训练数据的收集策略通常是部署现实世界机器学习算法中最重要却经常被忽视的部分。主动学习是收集训练数据的最佳方法,也是真正能够影响到底是失败的研究项目还是成功上线的算法的重要研究课题之一Lukas Biewald,cloudflower的创始人兼CEO向我们展示了他在图像识别方面进行的自主驾驶汽车的各个领域的主动学习的策略。

Lukas在训练自动驾驶系统数据中图像识别的密度标签
写在最后
百度在介绍完它们现今较为成功的自动驾驶技术成果后展示了这样一张图:
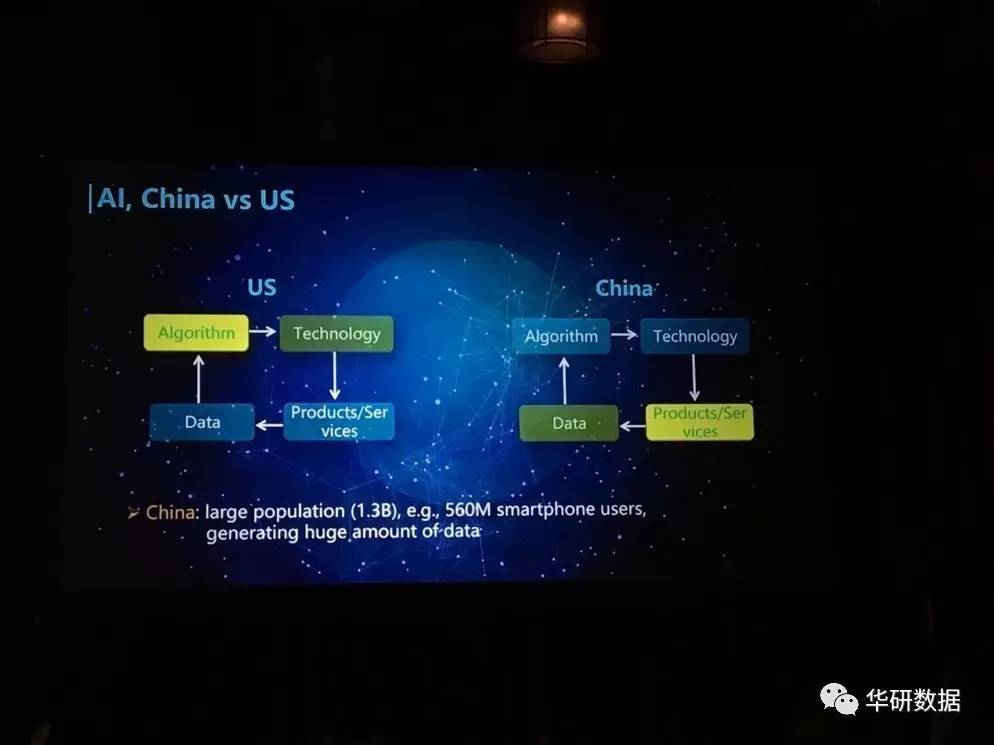
它表示了世界两大人工智能发展前列国家的优势劣势。从前我认为,在人工智能算法环节落后于美国的中国是在创新上一直会处于慢人一步的境地。然而,在此次大会和大会前后了解过了这么多中国蓬勃发展的大数据企业,以及回顾了人工智能20年理论发展的艰难,我才知道,现在的时代更重要的是数据的时代,有了庞大的数据量,便有了更多支持的理论依据和推动技术前行的动力,这是中国在人工智能发展道路上最得力的优势。大数据在中国各个领域的应用,也可以催生出更多新技术算法的可能性。百度的深度学习实验室主任林元庆说:未来AI的角逐,谁可以取得绝对的优势和先机已经不好说,因为中国正在积极将我们最大人口平台的海量数据投入到研究之中。
未来,你可能看到无人驾驶汽车、聊天机器人随处出现在生活中;你可以利用软件预测你的航班是否会延误、下周彩票的号码、甚至用机器在股市中来帮助你完成一次精确的量化投资… 就像每个人都会积累经验一样,AI也会随着数据的增长让人类的生活发生质变。
由于人类面临的很多问题都有不确定性和开放性,任何智能程度的机器终将无法完全取代人类,这就需要将人的作用和机器的作用共同发挥,让AI和人类的混合智能模式成为最终为人服务的最好方式。

新浪微博@华研数据
商务合作、原创文章转载请联系微信号minghui111777
投稿邮箱shangminghui@hooyuu.com
共有条评论 网友评论