

大数据管理技术是大数据应用的技术基础,而数据挖掘是大数据能够持续发展的动力。
时下,大数据的概念很火,围绕大数据生态有很多领域的创新与发展,但概括起来主要两点:大数据管理与大数据应用。

大数据不是一个新的概念,信息化的过程就会产生大量的数据,只不过这些数据没有很好的得到利用,也没有产生更大的价值。
在今天,由于物联网的快速发展,产生的数据量空前增大,而得益于计算技术的发展,使得这些数据可以被管理、可以被再一步利用。
因此,大数据管理技术是大数据应用的技术基础,而数据挖掘是大数据能够持续发展的动力。
跨界融合是时代的特征,很多企业界的朋友不论是不是搞信息化技术的,都已对大数据的概念耳熟能详,但实事求是讲,今天工厂大数据还处于非常尴尬的境地,我们总结了四多四少:

在企业应用大数据的过程中,主要是两方面的技术:大数据管理与大数据应用。这两点与传统的基于关系数据库的应用其实是完全一样的,只还不过大数据所采用的技术路线有所不同。
在所有的技术概念中最令人不好理解的莫过于“算法”和“模型”,今天我们先说说何为算法及工厂数据挖掘的算法。
百度说:算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。
知乎上有更加通俗的说法:办事情的方法,就叫算法。比如从北京到广州可以坐汽车去,也可以坐飞机去,还可以开虫洞跳过去,古代,只能骑马去,或者干脆走过去。
因此,对同样的问题,算法有优劣,但受制于技术及资源的限制,有些算法当前是没法实现的。
应用工厂大数据挖掘的算法有关联、回归、分类、聚类、预测、诊断六大类。
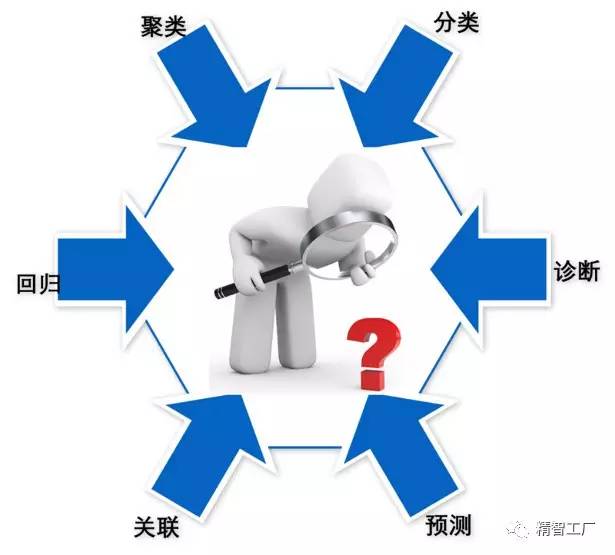
关联就是找到数据之间的隐藏的关联网。著名的例子莫过于“啤酒与尿布”了。按常规的思维或显然的经验,不会发现这两者之间有什么装系统,但通过信息挖掘的关联方法,就能找到二者这间的有关系。关联可分为简单关联、时序关联和因果关联。常用的关联算法有Apriori,FP-tree,HotSpot等。
回归如果给出两种或两种以上数据,相找出它们之间存的定量关系,这个方法叫做回归。比如大米的消耗量与人口之间的关系,可以认为是线性回归。常用的回归算法有线性回归、非线性回归、逐步回归、Logistic回归等。
分类提指数据数据的表现特征,对数据进行分类。类似于我们日常的行为:垃圾分类。分类在数据挖掘中有广泛的应用,开发出了很多经典的方法:决策树方法、神经网络方法、贝叶斯分类、K-近邻算法、支持向量机等。但不同的分类方法的适应性不同。
聚类物以类聚,说的就是聚类方法。即面向大量的样本数据,在预先没有确定分类的方法的背景下,根据数据的特征,确定样本大致可以分为几类。这几类数据之间有很大的差异性,而同一类数据之关有很大的相似性。因此,聚类是先计算样本可以分几类,然后再进行分类的方法。聚类的方法有:划分聚类、层次聚类、基于密度的聚类、基于网格的聚类和基于模型的聚类等。
预测预测应该是我们直观上很期待的一种方法,即我们可以具有“看见未来的天眼”。在数据挖掘中,预测是基于现有的历史数据,基于数据或基于模型对未来的数据进行预测。预测的前提是对客户事物规律的准确认识,了解内在本质及发展趋势。预测的方法分为时序分析方法和因果关系分析方法。
诊断故名思议,是指找出故障或异常的数据。在数据挖掘中,诊断的对象是离群点或称为孤立点。这类数据是不符合一般数据模型的点,与数据的其它部分不同或不一致。
比如在一个企业所有薪酬数据中,CEO的薪酬数估计会是一个离群点。在数据分析中,有时需要将离群点的影响变小,如工业现场温度值的一个跳变量,这肯定是一个数据噪声,应当在统计温度平均值时取掉。反过来,在轴承的低频振动信息中,一个突出信息号可能是某个地方出现磨损的表征,应当重视。
关于诊断的算法,大致可以分为基于统计学的方法或基于模型的方法、基于距离或邻近度的方法、基于偏差的方法、基于密度的方法和基于聚类的方法等。

有资料称,经典的十大算法为:C4.5,K-Means,SVM,Apriori,EM,PageRank,AdaBoost,KNN,NB和CART。近年来,大数据算法的研究又迎来了一个高潮,而人工智能、机器学习的发展为工厂大数据挖掘插上了翅膀。
参考文献:
周英、卓金武、卞月清.大数据挖掘系统方法与实例分析[M],北京:机械工业出版社,2016.
【重磅】《2017中国大数据产业生态地图暨中国大数据产业发展白皮书》权威发布!

【原创作品,转载请与社区联系】
共有条评论 网友评论