

2017中国工业大数据大会·钱塘峰会,由工信部、浙江省人民政府指导,中国工业经济联合会、信通院、互联网协会、浙江省经信委、萧山区人民政府共同主办,杭州市经信委、浙江省工业经济联合会、浙江省企业信息化促进会、萧山经济技术开发区、萧山科技城联合承办,于2017年5月5日在杭州国博中心顺利召开。会议围绕“数据驱动创新、融合引领发展”主题,进行探讨交流。现将国际大数据分析大会主席、IE云智能科技(杭州)有限公司首席数据管Dr.Christoph Schubert精彩演讲实录如下:

IE云智能首席数据管Dr.Christoph Schubert
大数据是什么,很多专家给我们做了定义,但从基础来讲,大数据有个比较简单的定义,我不可能把所有数据在一台电脑里处理完成,那有这么多数据,一台电脑肯定不够,要做一个分布式系统。把数据从一台电脑分布到很多电脑。
一、构建工业大数据应用程序的主要挑战
十几年前,2006年的一个项目是Hadoop,Hadoop是做大数据分析,简单讲就是API,是非常简单的界面。从2006年大数据时代就开始了。2004年就发布了MapReduce,他们的技术真的非常厉害,是我们的未来。
现在要处理大数据要有两个函数。2006年一位Doug Cutting的专家要做一个和Google搜索一样的商品系统是使用Hadoop名称的开放源代码,他看到Hadoop之后,认为可以用这样的算法处理系统。简单的编程模型,许多工具围绕核心Hadoop系统开发,就可以处理系统。而且它是开源的,所以可以在下面加很多的工具。
二、Hadoop架构
Hadoop有三个部分:HDFS、MapReduce、YARN。
HDFS是分布式文件,尽管可以把多台电脑同时处理数据,但也要知道哪台电脑有哪些数据,这就是HDFS做的事情;“两化”深度融合就是执行引擎,主要是运营任务;三是YARN,刚才说把一台电脑上的数据放在很多台电脑上,有时候是10台,有时候是20台,有时候是成千上万台,是很大的数据,所以不仅要跑一个任务,有时候要跑很多任务,所以,这就是YARN,它可以将任务分配到不同的就要节点。
在HDFS上面,我们发现要写MapReduce,很多时候写一模一样的代码,稍微跳一点点,写太多了浪费时间。不同的公司还要加不同新的工具,比如说SQL、ML、workflow,这就是简单的写代码的方法等等。这样的架构是2012年的。
另外,我们可以认为Hadoop就是批量处理,什么是批量处理呢?这和跑任务一个问题,是每天、每周还是每小时在跑任务。跑完任务之后肯定有新的数据对不对,哪里可以看出新的数据,还要继续跑任务,每个小时一直跑任务,这样是不是没有办法看最新的数据。我们可以做什么呢?可以做迷你微批量的处理方法,这个东西应该是Spark Streaming,我们可以认为这个数据是新的消息,但不是每次来一条信息就处理,我们要短暂,Spark等60到500毫秒,这样要控制机器也不够,所以我们要学习这个新数据,应该建立流式的方法。数据来了以后,要马上处理,这样就是可以在毫秒里,可以及时的处理数据。
批量处理数据还比较传统,Hadoop处理以后,要存在硬盘里。我们都知道把数据存在硬盘里需要很长的时间,Spark不是这样,我们要不停的处理数据。数据有附件,如果是数控机床,要有电压,要做机器检测。Spark是批量的处理方法,批量1.3以后,我们加一个新的版本是Spark Streaming,我们要分开Spark和Spark Streaming,可以通过Spark做批量和微批量。刚才说了Hadoop的系统,有很多工具,现在只需要一个Spark就行了。但还有一些销售的问题,Spark不可以陆续处理,要流式处理怎么办?这里面要APACHE Flink,这些工具都可以帮助我们做实时的处理。
工业大数据需要流式处理,批量处理就不行。我们可以看到最新的一个大数据测试,从大数据变成了工业大数据,大家还记得阿里巴巴的双11,发布了一个实时的动态数据,下单的货物可以在1.3毫秒之内就可以完成,这是非常厉害的流式处理技术。
大数据有非常多的挑战,数据出现之后,需要多长时间可以处理数据,大数据的处理要求非常高。如果把我们的数据全部放到一个数据中心,基本上没有办法做及时的处理,因为数据要从机器到控制系统,我们还要不断的升级处理方法。培养新的模型,处理数据等等,数据要处理在两个位置,要在机器附近,同时要在数据中心里。这应该怎么处理?
现在希望大家明白两个问题,数据处理要非常快,平时要放到数据中心里。这应该怎么办呢?如果要协调系统会非常麻烦,所以,现在有一个比较流行的架构SMACK堆栈。SMACK是什么意思?就是Spark、Mesos、Akka、Cassandra、Kafka,将这五个系统在一起可以处理大部分的数据问题。
SMACK堆栈可以认为是下一代的Hadoop或者是工业大数据上能替代Hadoop的系统。具体来说可以看到Akka,三个Akka形成一个kafka,然后流入到Spark Streaming,到操作集群,他们把数据从一个部分分成很多部分,这是一个call center完成的事情,可以从这里复制数据。最近两年国外非常流行SMACK,很多企业都在使用。
我想为大家介绍一下IE云,就是按照SMACK概念做的工业大数据方案。工业大数据可以分为四个部分:互联网、物联网、传感器网络、其他智能设备。在工业大数据里,不仅有机器数据,还有网上用户的数据等等;物联网和传感器网络有什么差别呢?物联网用TCIP技术,是叫传感器网络。
这个数据是什么格式?先把它放在Kafka里,要发一个消息,通过微信或者短信马上给他发一短信,但他现在没有时间看,一会儿还可以看。然后我给很多人发这个消息,kafka就给我这样的概念,我们把消息放到网络服务或者是微中心里,一边可以存在kafka,另一部分可以去Cassandra,或者去OSS,或者去NoSQL。现在我们按照要求分析数据,要非常快的分享数据,可以按照Flink或者是Strom,就是刚才提到的流式系统处理数据。如果时间要求不是很高,还可以通过Spark处理。Spark可以做微批量处理,也可以做批量处理。接下来通过Spark做比较类型,有可能要每秒都处理数据,都可以通过APACHE Spark。
我们要做数据分析,要学习Flink或者Storm,还有学习Grearpump。其中Storm是最复杂的。通过两种技术语言就可以处理所有的数据,普通的大数据速度不这么重要。

整理:袁媛校对:孙家淦
(本人根据演讲实录,未经发言嘉宾本人审核)

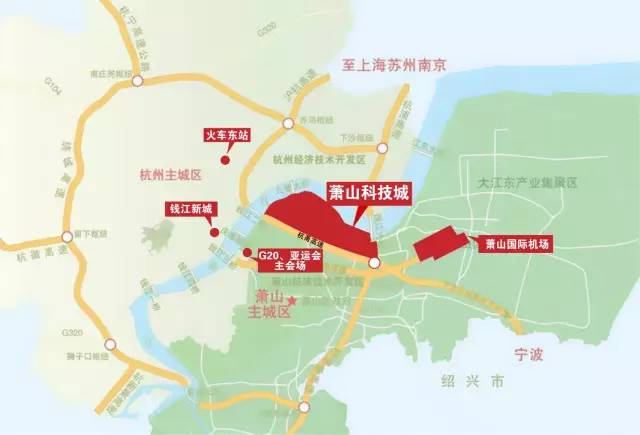
萧山科技城位于钱塘江南岸核心区,规划面积50.7平方公里(含水域面积13.6平方公里),拥有12公里生态江岸线,核心区距G20主会场13公里,距萧山国际机场10公里,是杭州南部的科技新城和萧山科技创新主平台。平台着眼于全球视野下高端要素的整合以及产城融合发展体制机制的创新,打造全国知名的工业制造转型升级示范区和试验平台,重点发展工业大数据等高端信息经济、机器人等智能装备制造,新材料新能源及影视文创等产业,同时,与传统制造业转型升级紧密结合,打造有利于产业创新驱动发展的产业生态。
萧山科技城内拥有以5所高校为依托的高教园区和大学科技园,以浙江国际影视制作中心、钱塘大数据交易中心、清华长三角研究院生物工程中心为载体的产业创新创业平台,同时,与上海陆家嘴集团、传化集团共同打造国际水准的现代化城市,区内拥有惠灵顿双语学校、国际社区、创业谷、星级酒店等丰富配套。萧山科技城面向未来的顶层设计和勇立潮头的拼搏精神,将造就杭州南部又一座宜居宜业的科技新城。

 点击上方“公众号”可以订阅哦!
点击上方“公众号”可以订阅哦!
共有条评论 网友评论