

文/ 陈广乾
兮易在企业大数据的实施中已做了好几年,从前端到后端,都有项目实践经验,下面我给大家分享一下兮易在企业大数据落地项目中的经验总结。

◆后台回复0505获取完整版PPT ◆
1大数据在业务不同阶段的表现形式
下面这个图是兮易在整个做项目的模式。
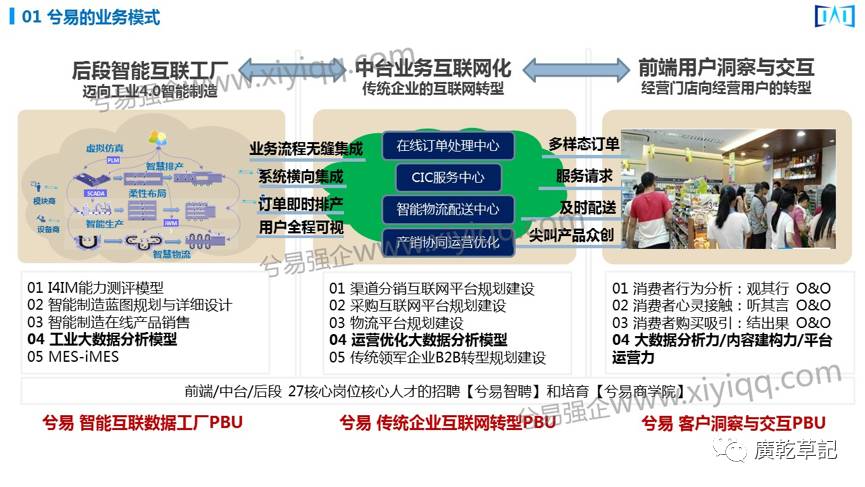
2013年、2014年我们主要做前端用户的洞察和交互,像国美在线、海尔等等C端;在2015、2016年往中台开始发展,做了一些工程机械的企业;今年逐渐向后端、向工业大数据领域,就是向社会级方向发展。这几年兮易在大数据上有丰富的实战经验,今天就具体说说工业大数据到底怎么在企业落地。
首先说一下我们开发的模型(该模型已经产品化)。
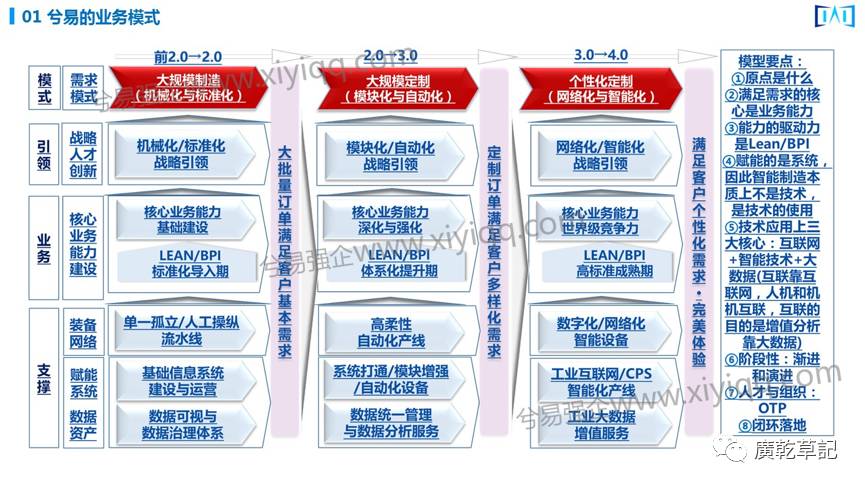
大数据和智能制造是一个事物的不同侧面,在不远未来中国制造业发展的关键期,他们具体表现为智能工厂、互联工厂和数据工厂。
我们根据上图开发了一个产品:给中国企业尤其是制造业做整体智能制造能力测评的模型。近日黄山市政府和我们还有赛迪研究院一起对黄山的大中型企业做智能制造的能力测评,就是依据这个模型。
这个模型里很重要的一块是大数据。在2.0时代还谈不到大数据,主要是数据分析;在2.0-3.0时代,数据的统一管理、数据的分析服务;在3.0时代,工业大数据的概念才出来,而且重要性也出来了。所以整个模型和企业的智能制造、数字化、网络化是密切相关的。
2前端:洞察用户,精准交互
下图是我们2013年开始做的前端的面向用户端的大数据基本业务模型。
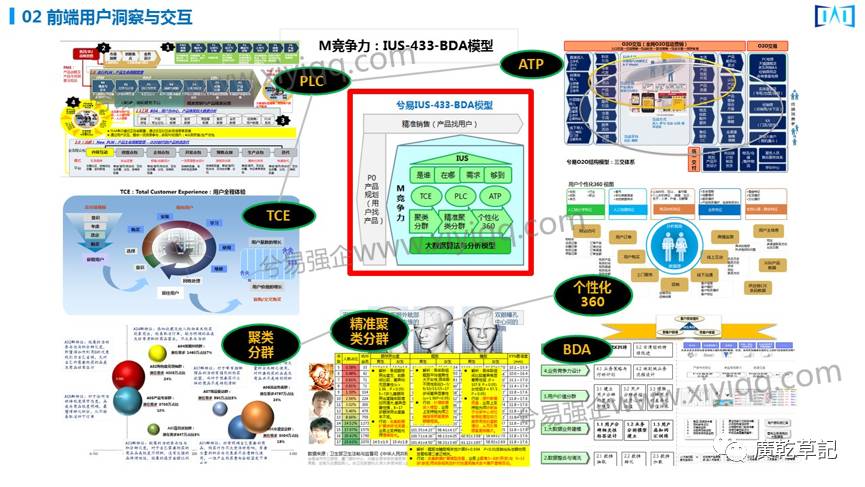
对于用户的理解过去在C端主要在经营渠道,后来逐渐由渠道发展到经营门店,再后来由于互联网的冲击,逐渐关注到传统的B2C企业连接用户。
但是用户到底是什么样的消费行为、什么样的喜好,怎么对他们进行更深的理解?
这时候对用户的洞察视角就和原来不同了,所以我们开发了一个IUS-433、BDA模型来洞察用户,给用户提供更好的服务,利用工具对用户精准的分类分群,并基于分类分群实行不同的算法,对算法进行不断的训练,从而为企业提供增值的服务。
下面我们来看一个具体的例子。这是我们做C端大数据模型所用的方法,通过这个来建立我们业务的需求模型。
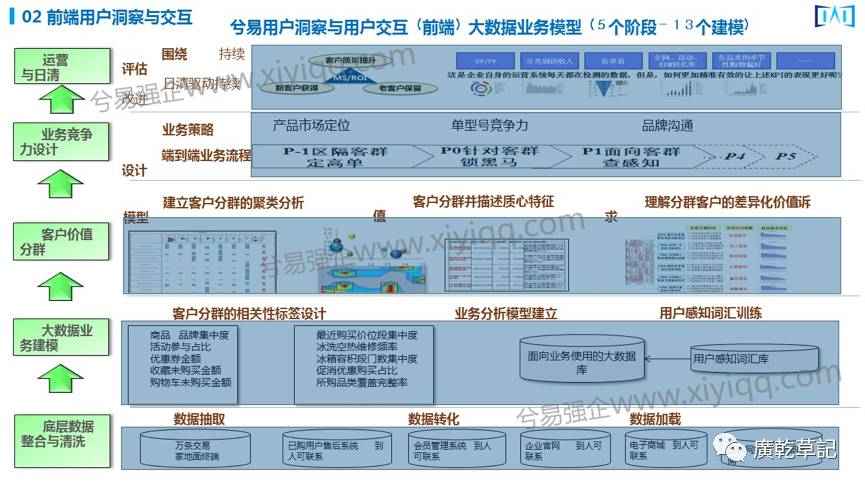
其实大数据模型的重要的基础前提是业务模型,我们在为客户比如国美、海尔、宝岛等建立的前端大数据模型时,需要对其业务模型再进一步研究。
我们在和清华、北大等大数据方面的博士沟通时了解到:他们对数据算法有很深研究,但是找不到数据后面的业务含义。原因是欠缺业务模型训练。业务模型训练是非常重要的,找到业务模型之后找数据模型,找到数据模型以后,才能提及为了解决这个业务问题我们需要用到哪些算法模型。
不是所有的数据都是大数据。其实社会数据早就有,质量数据也早就有。但是这堆数据里,到底能否通过建立我们原来认识不到的数据深度所提出来的新的算法,来解决新的价值增值问题?拿这些综合的算法分析,找出什么样的产品适合什么样的用户的这个模型,就是我们做前端大数据分析依据的一个基本的方法论。
将这个模型建立起来以后再做算法,算法形成模型以后,回过头来检测和实际的业务需求到底有多少差别——不断训练模型,一直到这个模型能解决业务问题,能产生实际效果,能完成目标,来形成一个闭环的循环,这个才是算法。
所以这是基于前端的用户标签如:相似性、消费行为的聚类性、分群性来做算法,这是基于算法模型。
我个人觉得数据和大数据的区别在于,除了刚才说的业务模型之外,还有是否存在一个非传统统计学所解决不了问题以外的新算法模型。
3中后端:产销协同,优化运营成本
2015年以后,我们逐渐往后端走了。
为什么传统工业大数据有它的复杂性,这个今天上午讲了很多,因为它很大的一个复杂性是要和企业的业务产生结合,而且要和它的工艺、生产、产品、产线形成结合,所以这里面有相当的专业性。
这里又涉及到一个业务模型。
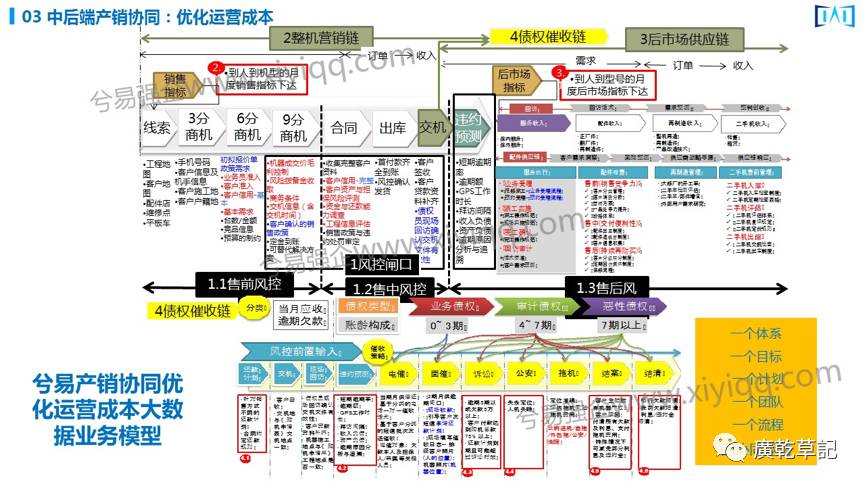
上图的模型是某工程机械行业的年销售大概40亿-50亿的核心业务,从业务模型上可以看什么数据能表征它业务的痛点,表征它业务痛点就意味着这个公司业务的效率降低,资金的流失、客户的流失这些都是可以从数据反应出来的。
传统咨询有时过分地侧重了业务和业务流程,没有进一步分析业务流程背后数据断点所造成的业务断点以及导致的损失,这是有了数据算法以后我们形成的新认识。
而运用大数据后的咨询诊断,把一个企业的业务模型做到第三级就可以了,(传统的DPM管理需要做到第五级岗位级操作级),这个例子中有100多个到三级的业务流程,在基于业务流程的失效造成企业大量经济损失挖掘背后的数据逻辑时,我们发现了它520个数据断点。
例如:下图的10个主要节点,构成了主机销售端到端的流程,而表征这个业务流程有没有核心竞争力的指标到底是什么。
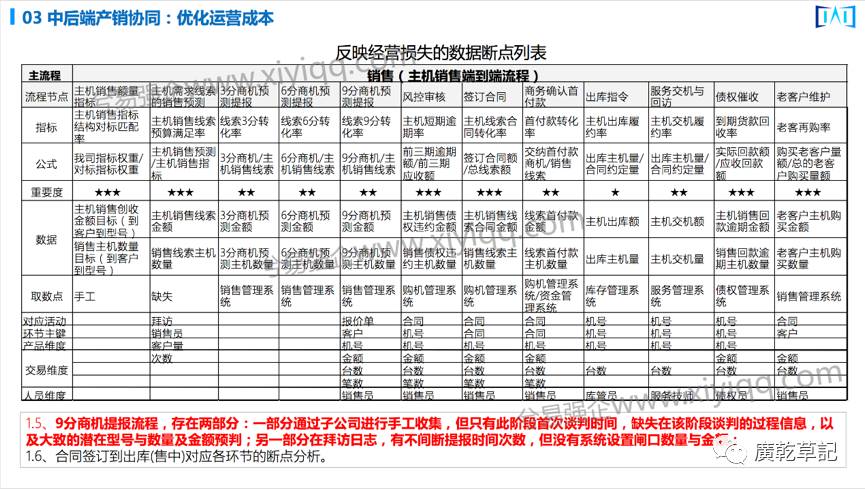
在三分商机预测的提报,有多少个买新的挖掘机的线索,能够让我签到合同,从这里面去找到数据相匹配业务的核心结构;
找到之后,再看对应数据现在是在系统里、还是手工的,这就要进入到所谓大数据几级架构的层面,进行数据的汇总和打通;
然后我们要建立模型,一定是有模型之后再做数据的清洗、加载、转化,这个数据的取出点、所对应的活动、所对应的产品维度、所对应的交易维度、所对应的人员维度,这些就构成了对于这个流程所表征的几乎是全维度的数据模型。
再往下走,进入数据模型以后,做算法之前,这里有很重要一步是了解业务规则,这对我们形成算法模型是非常重要的,如果不懂这个业务的规则,你很难做出算法模型。这也是我们和大量大学博士沟通感觉到的一个很大的痛点:算法很懂,但是不知道算法后面企业的特有业务规则是什么,还是做不出来让企业满意的算法模型,因为这里面就涉及到大量的业务规则。
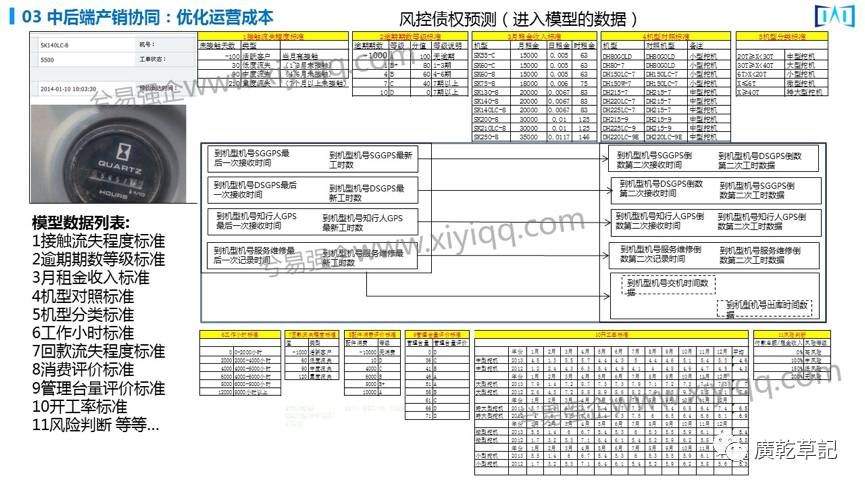
如果这个算法模型前面的规则大概有11个,那我们接受客户流失的标准怎么设定?
是合同的逾期也好、回款逾期也好,这个逾期到底怎么分等级,三个月的逾期就要电话催,六个月逾期要面催,九个月进入不良债权,可能要做诉讼,十二月可能要拖车——这是它特有的行业业务的规则,如果你不懂业务规则,做出来的算法也没有意义,所以这是大数据在企业落地的完整逻辑。
下面再走才是算法模型。
基于这个算法模型我们陆陆续续做了这么多年,提炼了上百种,但是哪些模型适合哪些业务,还是由业务本身和我们的算法团队共同来探讨,从而满足企业的目标。

我们的大数据模型是两个团队在组合作业:一个对一个企业的业务比较精通的业务团队,同时和一个业务团队紧密配合的算法团队。这是我今天说的第二个案例。
4后端:工业大数据,把控质量与成本
接下来又往后台走了,这张图是企业质量端到端的业务模型。
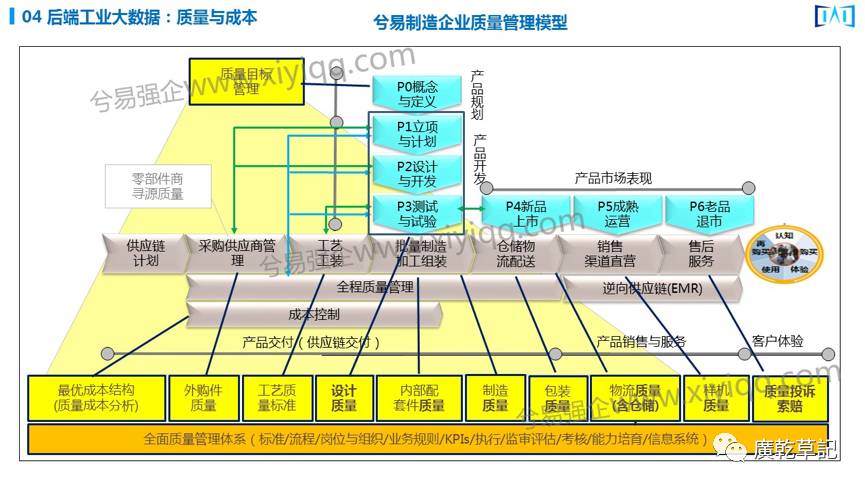
质量管理是制造企业像生命一样重要的核心业务流程。从最前端看,这个核心业务流程整个端到端的质量管理大概有11个主节点:从用户的质量投诉、索赔开始,一直到对供应商的质量控制,以及到质量成本分析。
所有这些流程到底和你的价值链是什么关系,这又是这个业务模型的一个难点:比如说内部配套件的质量涉及到我供应链里面的组装,最优成本结构涉及到我的质量目标,我的设计质量涉及到整个研发和设计,里面流程间有非常强的逻辑关系。
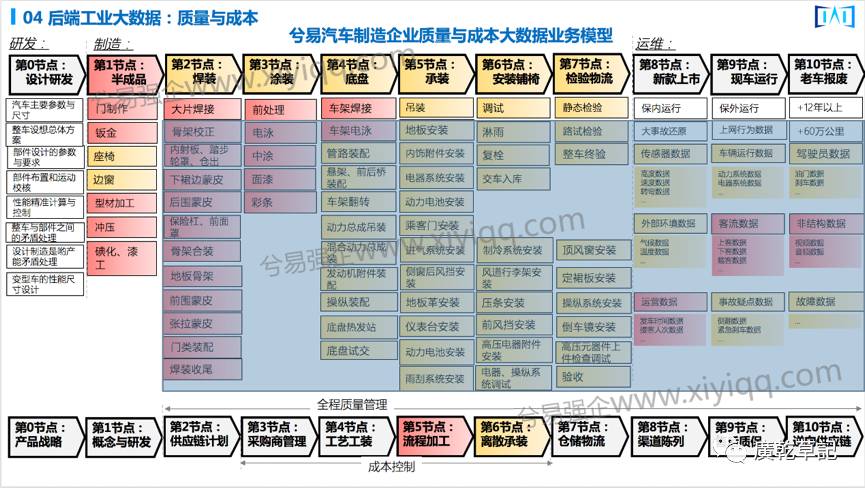
这个模型我们已在运用到一家汽车制造企业,目标是通过落地的大数据项目,能够形成最优的质量模型和导致这个质量提升之后所带来的最优的成本模型,现在这个项目正在进行当中。
5四年打磨建模方法论
这张片子是我们通过约4年的大数据实践,开发出的兮易的大数据建模方法论模型。

这个模型只是最初一步,它总共有8个步骤,55个板块,200多个模块。
在这个模型里总共大概整理了250多个细小的组件,这样为企业开发做大数据项目,效率就更快了。未来我们想进一步开发成一个方法论的产品模型。这是一个我们近几年走过来的,在企业大数据做法的一些经验,分享给大家。
6业务逻辑是落地关键
最后总结一点,真正做中国制造业的大数据项目,其实有几个关键的概念不能脱离:
企业要追求的是能带来多少效益,这是我们思考大数据的出发点;
从这个出发点出发,我们首先要了解业务,如果这个方法论建立起来以后,我们很快可以出一个先验模型,我们不断在这当中了解,在了解过程中,很重要的关键是和它目标相吻合的核心业务模型到底是什么,这是一个很重要的关键点。
抓住这个关键点,你把模型建到2层、3层就可以了,然后要迅速研究这个业务造成痛点、流血点、损失点的数据是什么样的体系。
这是一个很重要的逻辑,这个体系建立起来以后,这些数据就进入到传统的到底数据有没有用、它是系统采集的还是人工采集的、这个数据间的逻辑是怎么样的过程,这个数据模型建立后,能否实现它的业务模型,业务模型能否实现我们这次优化的老板要的目标。
这个逻辑需先在脑中完整的建立,然后才进入到我们所谓的大数据,再进入算法。在做算法模型以前,还要根据业务模型来摸准这个算法的业务规则是什么。

这是我们这几年走过来的经验和教训,和大家分享。掌握好这几个步骤,然后建立方法,不断地训练,不断与业务模型匹配,最后找到让企业满意的价值增值点,能够一定程度实现老板要的企业目标的改善——这个目标在刚才的例子里,有可能是质量最优曲线,有可能是成本最优曲线,有可能是经营的最佳效率,有可能是前端客户360的分析等等。
我今天就给大家说到这儿,谢谢!
————————End————————
声明:本文陈广乾先生原创,版权归属陈广乾先生所有
如需转载,请联系兮小易(微信ID:ce-xiyi)


点↙ 查看广乾学堂更多内容!
共有条评论 网友评论