
ERP大牛Luck在Psychophysiology上发表了一篇文章讨论目前大部分ERP研究中可能存在的根据总平均的图来选择分析的时间窗口和电极点的问题,以及数据分析中可能存在的总体错误概率和实验错误概率(familywise/experimentwise error rates)的问题。
第一部分 根据总平均结果来选择时间窗口和电极点
如何在任何一个ERP实验中发现显著的效应
由于ERP数据的单位是毫秒、微伏,其结果的差异也是在毫伏或者是毫秒这样的量级上,因此要达到0.05水平上的显著比较难。从另一方面来说,由于ERP数据的随机变异太多了,只要进行足够次数的分析,就有很大的机会在一些时间点和电极点上发现统计上显著的效应。这些效应可能是没有意义的,是不可重复或者不可预期的。对研究者、审稿人、甚至是对读者来说,很难区分一个显著效应是真实的还是无意义的。
基于这些问题,Simmons, Nelson, and Simonshon (2011)提出了『实验者自由度』的问题,实验者可以从很多不同方面去分析数据,如果数据分析方法是实验者对数据进行了初步检视之后确定的,那这将在很大程度上增加发现统计上显著但实际上无意义的效应(后称显著性假效应)的概率。由于ERP实验的数据很多,其数据分析就比行为实验要自由得多,发现显著性假效应的概率就大大增加了。
一个实例
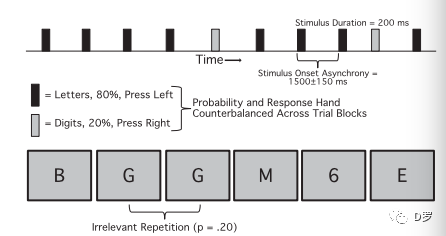
如上图所示,字母和数字在注意点的位置呈现,呈现时间为200ms,SOA为1500正负150ms。其中一种刺激类别出现较少(20%),另一类别出现较多(80%),被试对不同类型的刺激用左手或者右手进行按键反应。频繁或较少的类别的刺激和反应手都做了平衡。在频繁出现的字母或者数字中,偶尔会出现连续重复,比如图中的字母G。实验的目的是分析被试能否检测到这些重复,即重复与不重复是否存在不同的加工。与之前的研究结果相类似,低频刺激比高频刺激诱发了更大的N2和P3。更重要的是,重复比非重复诱发了更大的P1,特别是在右半球。另外,重复比非重复在中央和顶部电极点诱发更大的P2。因此P1和P2的结果表明在高频刺激系列中的重复刺激可以被检测到,即便它们与任务无关。而且这个结果表明,对重复的检测发生得很早(100ms左右),并且会影响后面的加工(P2)。结果如下图。
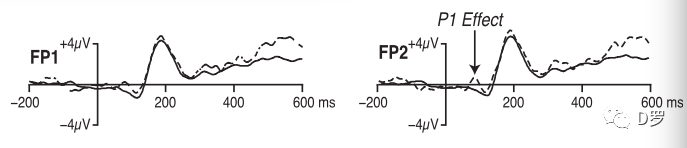
这听起来似乎是一个完美的合理的故事,数据分析也没有任何问题。但实际情况是,这些数据都是随机的,作者随机的将重复与不重复安排到实验中。换句话说,作者模拟了一个虚无假设为真的实验。因此,得到的P1和P2的效应都是没有任何意义的。
这样分析数据的问题在于:研究者先观察了总平均的状况,然后来选择时间窗口和电极点进行分析。
这就带来了隐性多重比较问题(multiple implicit comparisons),即实验者通过视觉对ERP波形进行了上千次的比较,然后对那些视觉上看起来有差异的地方进行统计检验。
一个研究者如果不想获得显著性假效应,那么他应该在实验前有一个预期,而不是通过观察总平均数据的方法来选择分析的时间窗口和电极点,对预期以外的显著性效应都应视为是建议性的,直到这些意外的效应被重复。
如何避免测量和分析程序出现偏差
一、提前设定测量参数
如果有可能,在看到数据之前预先设定分析的时间窗口和电极点。这种方法有时候比较难,因为不同实验的效应可能不同,成分的潜伏期可能不同。并且,许多研究都很新,以至于没有很好的可供参考的研究。
二、功能定位(functional localizers)
功能定位的方法在神经成像的研究中比较常见。在研究中设置一个功能定位条件来决定某个效应的时间窗口和电极点。比如:想要考察面孔加工中的某些微小差异在N170上的表现,可以在实验中设置一个非面孔条件,通过面孔与非面孔的对比来决定N170的时间窗口和头皮分布。该方法的优点是把不同被试在N170的潜伏期和头皮分布上的差异考虑在内。但是该方法假设功能定位条件下的时间窗口和头皮分布与研究感兴趣的条件下的分布是相同的,并不是所有的研究都符合这个假设。
合并定位(collapsed localizers)
一个与功能定位类似的方法是合并定位,把所要比较的所有条件的波形进行平均,通过平均后的波形来定义时间窗口和电极点等分析参数,然后将这些参数应用到未合并的不同的条件中去。虽然在有的情形中这种方法可能有问题(详见:Luck, 2014),但是对大部分无法依据前人文献来定义分析参数的研究是适用的。
独立于时间窗口的测量(window-independent measures)
一些ERP数据分析方法依赖于时间窗口的设置,另一些则独立于时间窗口。比如:平均波幅在很大程度上依赖于测量的时间窗口,而峰值分析则不是那么依赖于时间窗口设置的精确性,特别是对那些波峰很明显且峰值很大的成分进行测量时。从另一方面来说,平均波幅检验要优于峰值检验,因为峰值检验对高频噪音很敏感。如果实在没有好的办法来确定时间窗口,那么使用峰值测量可能更合适。在采用平均波幅分析时,如果能够表明平均波幅的统计显著性不受时间窗口设置的影响那就更好了。
单变量方法(the mass univariate approach)
单变量方法是对每个电极点上的每个时间点分别进行t检验,并且采用某种校正方法控制多重比较带来的I类错误。传统的bonferroni校正过于保守,现在有很多其它的校正方法,并且是免费开源的,比如Mass Univariate Toolbox和FieldTrip。这些方法仍然显得十分的保守,但是如果没有很好的先验信息来指导时间窗口和电极点的选择,这些方法便是最好的方法。
数学方法分离潜在成分
比如源定位、独立成分分析,和空间主成分分析等。
重复
最后也是最重要的方法,就是最简单最古老的方法,重复。
第二部分 总体错误概率和实验错误概率
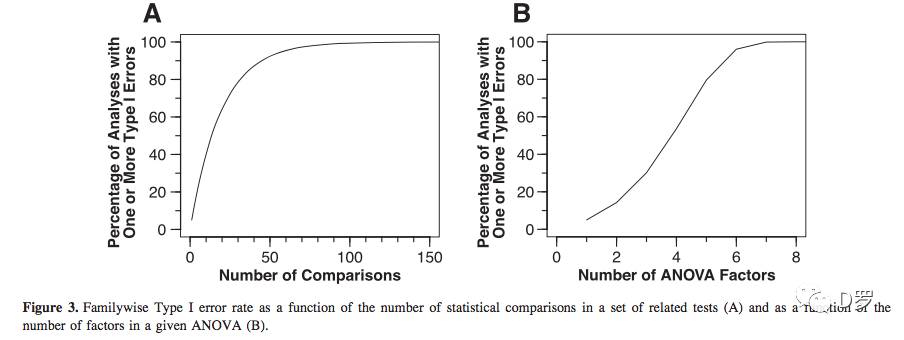
总体错误概率(Familywise error rate)是指在一组相关的分析中(比如单个ANOVA分析中得到的主效应和交互效应),一个或者多个效应犯I类错误的概率。比如,一个3因素ANOVA分析包含3个主效应,4个交互作用,可能会导致超过30%。
实验错误概率(Experimentwise error rate)是指在一个实验中所做的所有分析中有一个或者多个效应犯I类错误的概率。如果进行两个3因素方差分析,实验错误概率可能超过50%。也就是说14个主效应和交互作用中可能没有一个是真正的有意义的效应,我们仍然有接近50%的概率发现至少1个显著性假效应。
表1和图3分别说明了方差分析中的效应数和因子数与I类错误间的关系

如何减少总体错误概率和实验错误概率
一、减少因素的个数。在不降低统计效力的情形下,可以减少方差分析中的因素个数。比如,那些用来平衡的因素就可以不纳入方差分析。另外,那些虽然是实验的一部分,但是对检验主要假设没有贡献的因素也可以被排除。比如,有时候电极点并不是重要的信息,便可以排除。
二、采用差异分数来减少方差分析中的因素个数。基于差异的策略在ERP研究中已经被广泛运用。比如N2pc成分,典型的N2pc就被定义为对侧电极点与同侧电极点波幅的差异。
三、减少不必要的分析。比如同时分析波幅和潜伏期可能导致实验错误概率加倍,同时分析两个成分也一样。如果一个实验设计来就是测量P3的波幅,那么观察到的P3潜伏期的差异或者其他成分的差异就必须要小心对待。
四、减少因素的损失与获益。ERP研究者要将数据分析聚集在检验与某个理论相关的重要效应上。许多的统计教材鼓励大家使用层级策略,先对所有可能的因素进行一个方差分析,随后对那些显著的效应进行进一步分析。从减少实验错误率的角度来说,这不是一个好的策略。相反,研究者应该聚集在检验某个理论相关的特定的主效应和交互效应上,把其它的显著的效应都视为可能性的而非结论性的效应。
五、重复,审稿人和编辑的作用。很显然,最具有说服力的方法是重复。当然,重复需要花时间,花金钱,从短期效应来说研究者进行重复的动机不强。但是,当杂志的编辑和审稿人发现研究者的数据分析策略可能会产生较高的实验错误率时,原则上可以要求作者进行重复。
原文信息:
How to get statistically significant effects in any ERP experiment (and why you shouldnt)
AbstractERP experiments generate massive datasets, often containing thousands of values for each participant, even after averaging. The richness of these datasets can be very useful in testing sophisticated hypotheses, but this richness also creates many opportunities to obtain effects that are statistically significant but do not reflect true differences among groups or conditions (bogus effects). The purpose of this paper is to demonstrate how common and seemingly innocuous methods for quantifying and analyzing ERP effects can lead to very high rates of significant but bogus effects, with the likelihood of obtaining at least one such bogus effect exceeding 50% in many experiments. We focus on two specific problems: using the grand-averaged data to select the time windows and electrode sites for quantifying component amplitudes and latencies, and using one or more multifactor statistical analyses. Reanalyses of prior data and simulations of typical experimental designs are used to show how these problems can greatly increase the likelihood of significant but bogus results. Several strategies are described for avoiding these problems and for increasing the likelihood that significant effects actually reflect true differences among groups or conditions.
Cite:Luck, S. J., & Gaspelin, N. (2017). How to get statistically significant effects in any ERP experiment (and why you shouldnt).Psychophysiology,54(1), 146-157.
共有条评论 网友评论